
I’ve recently created a piece of software for creating fractal animations. The full source code and a description of its features can be found at the project’s GitHub page. On this page, however, I’ll explain the technical details behind the algorithm used by the core engine of Incendium to generate its fractals. If you want a non-technical overview, please check out the GitHub page. In essense, the program works by drawing a bunch of polygons unto an empty frame. There are two central problems here, how to choose which polygons to draw, and to figure out where to draw them.
We start with a regular  -gon (called depth
-gon (called depth  ) drawn with its center at the origin
) drawn with its center at the origin 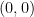 , and from each of its vertices, we draw another regular n-gon (it does not need to be the same for every depth). These new polygons have center at the vertices of the old polygon and have depth
, and from each of its vertices, we draw another regular n-gon (it does not need to be the same for every depth). These new polygons have center at the vertices of the old polygon and have depth  , and in general a polygon at depth
, and in general a polygon at depth  will have children of depth
will have children of depth  . We continue doing this process until we’ve reached the specified fractal depth, giving us images such as (shown from depth to
. We continue doing this process until we’ve reached the specified fractal depth, giving us images such as (shown from depth to  ):
):

Note that this image uses triangles, rather than the more general -gon. This is because the math is pretty much the same for any , and triangles are easier to visualize. Note that we’ve drawn all triangles here – what is a good method to choose which of these triangles to choose?
Choosing which polygons to draw
First of all, let’s label the polygons accordingly in a systematic fashion. Let’s label the very first -gon the empty string  . Its children will be appended the characters
. Its children will be appended the characters  , meaning that the children of the root node are called
, meaning that the children of the root node are called  . The children of the polygon represented by the string
. The children of the polygon represented by the string  will likewise be appended these characters, and thus be called
will likewise be appended these characters, and thus be called  . Adding these labels to the above drawing yields:
. Adding these labels to the above drawing yields:

Note that the length of the string  is directly related to the depth of the polygon represented by that string, that is
is directly related to the depth of the polygon represented by that string, that is  for some fractal depth
for some fractal depth  . For a constant polygon degree throughout the fractal, we will have a polygon for every possible string
. For a constant polygon degree throughout the fractal, we will have a polygon for every possible string  . Thus we’ve reduced the problem of determining which polygon to draw to choosing a language
. Thus we’ve reduced the problem of determining which polygon to draw to choosing a language  and drawing all the polygons represented by the strings in
and drawing all the polygons represented by the strings in  . Please note that since the polygon degree isn’t necessarily constant, we can’t be sure that all such strings actually exist in the fractal, but there is a relatively simple workaround.
. Please note that since the polygon degree isn’t necessarily constant, we can’t be sure that all such strings actually exist in the fractal, but there is a relatively simple workaround.
To do this, we employ the help of regular expressions. While this technically limits the class of possible languages, it is a very simple approach, so we’re sticking with it. So, given some regular expression  we draw all polygons represented by all the strings in
we draw all polygons represented by all the strings in  . Shown here is the regular expression
. Shown here is the regular expression  which only accepts all regular expressions that contain a 1:
which only accepts all regular expressions that contain a 1:

Where do we draw them?

Still, it’s not enough to just know which polygons to draw, we also need to know where to draw them. The root polygon is by definition placed at , so its location is trivial. It’s children are drawn with their centers at the vertices of the root polygon, which seems to suggest we need the position of these. Assume we have some polygon with “radius”  and rotation
and rotation  . We know that all the vertices of the polygon lie on the graph for the circumscribed circle of the polygon. Therefore, we can easily derive the following formulas for the position of the vertices using trigonometry:
. We know that all the vertices of the polygon lie on the graph for the circumscribed circle of the polygon. Therefore, we can easily derive the following formulas for the position of the vertices using trigonometry:





And in general,

Where  is the
is the  -th vertex.
-th vertex.
Now, assume we have some polygon at depth  represented by some regular expression
represented by some regular expression  , and we want to know the position of its vertices. We know the origin of this polygon is given by the polygon at depth
, and we want to know the position of its vertices. We know the origin of this polygon is given by the polygon at depth 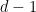 . This other polygon is naturally represented by the regular expression
. This other polygon is naturally represented by the regular expression  , so its position is
, so its position is  . We know the character
. We know the character 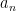 represents which vertex we have (0 being the first vertex, 1 being the next vertex etc.). Therefore, we can write the following recursive relation:
represents which vertex we have (0 being the first vertex, 1 being the next vertex etc.). Therefore, we can write the following recursive relation:


Where  is the radius for the polygon represented by , and
is the radius for the polygon represented by , and  is the angle – these will be investigated later. This recursive relation has the base-case
is the angle – these will be investigated later. This recursive relation has the base-case  and implementing it is straight-forward (shown here in pseudo-code):
and implementing it is straight-forward (shown here in pseudo-code):
function positionFromRegex(R)
if len(R) == 0: return (0,0)
return positionFromRegex(R')
+ ( r(R) * cos(theta(R) + a_k/n * 2pi),
r(R) * sin(theta(R) + a_k/n * 2pi) )
It’s the size that matters
In the previous section, we just used to denote the radius of the polygon represented by the regular expression , we’ll now derive an expression for this function. First note that the size should only be dependent on the depth. Strings of the same depth should have the same size – we don’t want  to be larger than
to be larger than  . Therefore, we can assume that the argument for is a number, so we have
. Therefore, we can assume that the argument for is a number, so we have  . Obviously, we want
. Obviously, we want  to be the largest radius (for the root polygon), and we label this
to be the largest radius (for the root polygon), and we label this 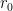 , so
, so  . We also want this function to be strictly decreasing as
. We also want this function to be strictly decreasing as  , so
, so  for every
for every  . Finally, we want to structure we’re designing to be a fractal – it should converge towards the same points as .
. Finally, we want to structure we’re designing to be a fractal – it should converge towards the same points as .
Note that the maximum distance from the origin that the first polygon can get is , and therefore the maximum distance any polygon at depth can get from the origin is  and so on… Therefore the maximum distance any polygon at an arbitrary depth can get is
and so on… Therefore the maximum distance any polygon at an arbitrary depth can get is  . And since we want our fractal to be finite we require this sum to be finite, that is:
. And since we want our fractal to be finite we require this sum to be finite, that is:


For some finite constant  . This looks an awful lot like infinite geometric series. While it’s not the exclusive solution for , it is a possible one giving us the following expression for
. This looks an awful lot like infinite geometric series. While it’s not the exclusive solution for , it is a possible one giving us the following expression for  :
:

For some constant ![\rho \in [0,1]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . We call this constant the size decay of the fractal.
. We call this constant the size decay of the fractal.
You spin my head right round…
We’ve just derived the expression for the function and now we’ll do the same for . Using a similar argument as in the previous section, we want the argument of to be the length of the regular expression . We also want the rotation to not be very chaotic, as the assumption is that this won’t create beautiful fractals. Therefore we want the fractals to rotate a constant amount at every subsequent depth. This means we can derive the following expression for  :
:

Where ![\theta_0 \in [0, 2\pi]](https://s0.wp.com/latex.php?latex=%5Ctheta_0+%5Cin+%5B0%2C+2%5Cpi%5D&bg=ffffff&fg=000000&s=0&c=20201002) is a constant. We call this constant the rotation of the fractal.
is a constant. We call this constant the rotation of the fractal.
Putting it all together
Now we’ve derived expressions for the two unknown functions and we get the following final recursive relation for the position  of a polygon represented by the regular expression
of a polygon represented by the regular expression  :
:
![P_{a_0 a_1 a_2 ... a_k}[x] = P_{a_0 a_1 a_2 ... a_{k-1}}[x] +](https://s0.wp.com/latex.php?latex=P_%7Ba_0+a_1+a_2+...+a_k%7D%5Bx%5D+%3D+P_%7Ba_0+a_1+a_2+...+a_%7Bk-1%7D%7D%5Bx%5D+%2B+&bg=ffffff&fg=000000&s=0&c=20201002)

![P_{a_0 a_1 a_2 ... a_k}[y] = P_{a_0 a_1 a_2 ... a_{k-1}}[y] +](https://s0.wp.com/latex.php?latex=P_%7Ba_0+a_1+a_2+...+a_k%7D%5By%5D+%3D+P_%7Ba_0+a_1+a_2+...+a_%7Bk-1%7D%7D%5By%5D+%2B+&bg=ffffff&fg=000000&s=0&c=20201002)

I’ve split it into two lines for x and y to make it more comprehensible. We can also write this in pseudo-code:
function positionFromRegex(R)
k = len(R)
if k == 0: return (0,0)
return positionFromRegex(R')
+ ( r_0 * rho^k * cos(theta_0 * k + a_k/n * 2pi),
r_0 * rho^k * sin(theta_0 * k + a_k/n * 2pi) )
This has been implemented in the source code in the function called getPositionFromString();.





 corresponds to the Fibonacci sequence, and
corresponds to the Fibonacci sequence, and  corresponds to the Lucas numbers, first index truncated.
corresponds to the Lucas numbers, first index truncated.


 .
. , by definition.
, by definition.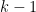 , and
, and 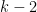 to get:
to get:  . We use the definition of
. We use the definition of  and
and  , and get
, and get
 . Which is what we wanted to show.
. Which is what we wanted to show.  .
. .
. . Which is what we wanted to show.
. Which is what we wanted to show. , using the induction hypothesis. Multiplying, we get
, using the induction hypothesis. Multiplying, we get  . Using lemma 2, we find
. Using lemma 2, we find  .
. , then proving
, then proving  .
. , because of lemma 2. Because of lemma 1.2, we have
, because of lemma 2. Because of lemma 1.2, we have  , so we get
, so we get  . This implies that
. This implies that  because of lemma 2, which implies that
because of lemma 2, which implies that  .
. 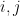 . Define a sequence
. Define a sequence  and
and  . That is, we start with two initial values, and repeatedly subtract the smallest value from the largest value. Since
. That is, we start with two initial values, and repeatedly subtract the smallest value from the largest value. Since  , we know that
, we know that  for all
for all  no matter our choice of
no matter our choice of  and the invariant that any term must be positive).
and the invariant that any term must be positive).
 color pixel by
color pixel by  which can be calculated using a simple recursive procedure:
which can be calculated using a simple recursive procedure:
 , and every node
, and every node 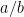 has a left child
has a left child  and right child
and right child  .
.
 is a left child, then
is a left child, then  , and if it’s a right child then
, and if it’s a right child then  . This allows us to determine the parent node of a given node.
. This allows us to determine the parent node of a given node. . Similarly, if
. Similarly, if  , then its parent is
, then its parent is  . Notice that at each step, we subtract the smaller number from the larger number, and we terminate the procedure when we reach the fraction
. Notice that at each step, we subtract the smaller number from the larger number, and we terminate the procedure when we reach the fraction  does not exist in the Calkin-Wilf tree. To circumvent this issue, we convert our input node to the equivalent rational number in lowest common terms.
does not exist in the Calkin-Wilf tree. To circumvent this issue, we convert our input node to the equivalent rational number in lowest common terms.
 and the number of iterations it took for the point to converge – and saturation/value decreased with increasing magnitude
and the number of iterations it took for the point to converge – and saturation/value decreased with increasing magnitude  .
. , and saturation/value inversely proportional to only the edit distance.
, and saturation/value inversely proportional to only the edit distance.





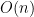 algorithm, which works much better than the modified
algorithm, which works much better than the modified  algorithm for
algorithm for  strings for some depth
strings for some depth  (images of size 8192px x 8192px) we need to save
(images of size 8192px x 8192px) we need to save  a single string of length
a single string of length 
 pixels in total, resulting in a heap usage
pixels in total, resulting in a heap usage  , as it would require
, as it would require  and store them in an array
and store them in an array  .
.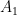 which recognizes strings of length
which recognizes strings of length 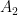 that recognizes all strings of length
that recognizes all strings of length  . Because now that we have
. Because now that we have  . This can be written in Java-like pseudo-code as:
. This can be written in Java-like pseudo-code as: . The other advantage is that there is no reason to save all the Strings in an array, making it possible to make much larger images. To view the algorithm in further detail I encourage you to go read
. The other advantage is that there is no reason to save all the Strings in an array, making it possible to make much larger images. To view the algorithm in further detail I encourage you to go read 






{kind=link}